
本文的閱讀等級:高級
美國作家梭羅 (Henry D. Thoreau) 在《湖濱散記》談到他的幽居生活時,說道[1]:
我們的生活消耗在瑣碎之中。一個老實的人除了十指之外,便不必有更大的數字了,頂多加上十個足趾,其餘不妨勉強一下。簡單,簡單,簡單啊!我說,最好你的事祇兩三件,不要一百件或一千件;不必一百萬一百萬地計算,半打不夠計算嗎?總之,賬目可以記在大拇指甲上就好了。
我們也許不能複製梭羅在瓦爾登湖 (Walden) 的簡單生活,但是我們永遠可以通過化繁為簡來改善現況。處於資訊爆炸的時代,我們不免要面對變數很多且樣本數很大的資料。在分析高維度 (變數很多) 數據時,降維 (dimension reduction) 常是一個必要的前處理工作。主成分分析 (principal components analysis,簡稱 PCA) 由英國統計學家皮爾生 (Karl Pearson) 於1901年提出[2],是一種降低數據維度的有效技術。主成分分析的主要構想是分析共變異數矩陣 (covariance matrix) 的特徵性質 (見“共變異數矩陣與常態分布”),以得出數據的主成分 (即特徵向量) 與它們的權值 (即特徵值);透過保留低階主成分 (對應大特徵值),捨棄高階主成分 (對應小特徵值),達到減少數據集維度,同時保留最大數據集變異的目的。本文從線性代數觀點介紹主成分分析,並討論實際應用時可能遭遇的一些問題。
假設我們有一筆維數等於 

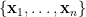


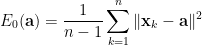
上式中,誤差平方和除以 
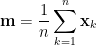
稱為樣本平均數向量。證明如下:

根據樣本平均數向量 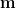
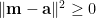

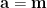
數據點 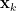
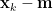
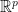

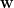


其中 
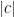
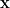
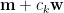
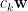
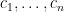
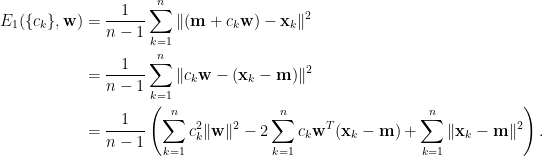
因為 

由此解得

從幾何觀點解釋,

圖1 正交投影即為最佳近似
接下來我們尋找使 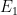

上面使用了 

稱為樣本共變異數矩陣。乘開上式,確認 
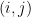



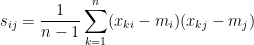
其中 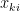


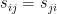
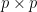

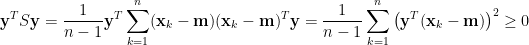
即知 

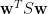
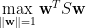
解法如下 (另一個解法見“Hermitian 矩陣特徵值的變化界定”)。使用 Lagrange 乘數法 (見“Lagrange 乘數法”),定義
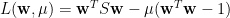
其中 
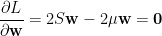
可得
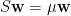
直線 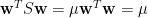



如果我們想獲得較為精確的近似結果,以上過程可推廣至更高維度。考慮

其中 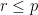

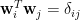


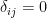
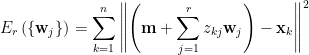
根據正交原則,組合係數 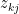



緊接的任務要解出約束二次型:
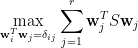
仍然使用 Lagrange 乘數法,定義

其中 

對於 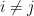
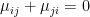
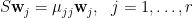
換句話說,當 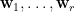




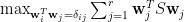

我們以 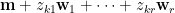

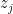
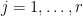

再來計算
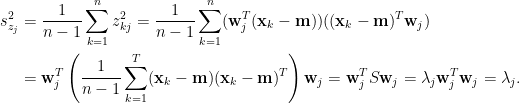
所以說,特徵值 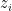

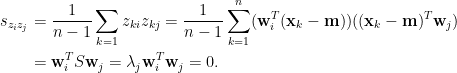
給定維度等於
- 計算樣本平均
,定義
階離差矩陣
,
。
- 將
,
其中
是特徵值矩陣,
代表主成分的權值,
是單範正交特徵向量構成的
。圖2顯示
的資料散布圖,樣本平均數向量
和
。圖中橢圓的長軸平方與短軸平方之比等於主成分係數
的變異數與
的變異數之比,即
。

圖2 資料散布圖與主成分
- 定義
,其中
,因此
。
上式等號兩邊右乘
,可得
。換一個說法,數據點
。
主成分係數
是離差
的座標向量。

最後還有一些與實際應用面相關的細節需要釐清。
- 我們應當保留多少低階主成分 (對應大特徵值的特徵向量)?也就是說,如何選擇
的變異與原始數據
的變異的比例。譬如,選擇最小的
,
表示我們保留了 80% 的數據變異。
- 若數據的變數具有不同的變異,主成分方向會受到變異大的變數所決定。如欲排除這個影響,我們可以用樣本相關矩陣取代樣本共變異數矩陣。在套用主成分分析之前,預先將每一變數予以標準化 (standardized),如下:
其中
是第
。標準化後的數據集的樣本共變異數矩陣即為樣本相關矩陣
。
請讀者自行驗證
的
。
上面使用了跡數循環不變性
(見“跡數的性質與應用”),最後一個等式係因
。
- 如何得到數值穩定的主成分
,權值
,以及主成分係數
,
?答案是奇異值分解 (singular value decomposition)。通過主成分分析與奇異值分解的關係可以顯現主成分分析隱含的其他訊息 (見“主成分分析與奇異值分解”)。

註解
[1] Henry D. Thoreau 的 Walden,原文如下:“Our life is frittered away by detail. An honest man has hardly need to count more than his ten fingers, or in extreme cases he may add his ten toes, and lump the rest. Simplicity, simplicity, simplicity! I say, let your affairs be as two or three, and not a hundred or a thousand; instead of a million count half a dozen, and keep your accounts on your thumb-nail.” 中譯取自《湖濱散記》,吳明實譯,今日世界出版社,1978年,83頁。
[2] 維基百科:主成分分析
[3]

[4] 考慮
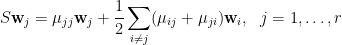
令 

將條件方程組寫成矩陣形式:

因為 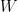




將實對稱矩陣 
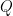
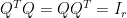
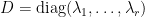


上面我們令 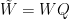
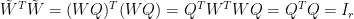


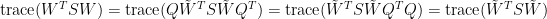
證明 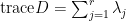
[5] 假設我們已經求得最大化 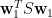


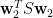
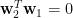

其中 

上式左乘 

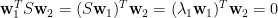

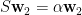


最近又去聽了微積分的課,剛好聽到了講述simpison數值積分方法。數值積分方法特別可以處理非平滑的函數數據。其中可達到一定精確度的simpison方法,用了拋物線來近似分散的數據,其手法就是揉合上述的正交投影以及黎曼和的概念。因為正交投影,所以可以控制誤差到一定範圍內,黎曼積分也就可以派上用場。只是我好奇的是,因為訊號處理常常用到傅立葉分析來搜尋出有用的訊號,那麼是否可以用傅立葉分析來做數值積分呢?
Simpson 積分法則的原理是Newton-Cotes公式: ,
, ,
, 。通常我們使用一內插多項式來近似
。通常我們使用一內插多項式來近似 以得到
以得到 的計算公式。這個式子看起來很像是Hilbert空間的函數近似問題:最小化
的計算公式。這個式子看起來很像是Hilbert空間的函數近似問題:最小化 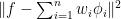 ,
,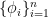 是我們喜愛的基底,最佳近似確實是
是我們喜愛的基底,最佳近似確實是 在這個基底所擴張的子空間的正交投影。
在這個基底所擴張的子空間的正交投影。
傅立葉變換是一種積分變換,它可以用來計算函數近似的三角級數(trigonometric series),或證明一些定理,但我不知道是否亦可作數值積分用。
傅立葉積分轉換是把時域的資訊轉換成頻率域的資訊,你可以理解成他把時域中某個頻率的能量積分然後放到頻率域中去。所以沒錯,傅立葉轉換本身是有積分的效果在的,只是他把要拿來積分的東西分離成正交的獨立函數分別處理。
https://zh.wikipedia.org/wiki/%E8%B0%B1%E5%AF%86%E5%BA%A6
https://zh.wikipedia.org/wiki/%E5%B8%95%E5%A1%9E%E7%93%A6%E5%B0%94%E5%AE%9A%E7%90%86
請問主成分分析是否一定要進行標準化?
如果變數的尺規(scale)相似,譬如,全部都是EEG訊號,那麼使用共變異數矩陣即可。如果變數的尺規差異很大,譬如,年所得,年齡,體重,那麼應該使用相關係數矩陣(即標準化後的共變異數矩陣)。
周老師,我有兩個問題:
1)對E1求ck的偏導數是否第一個2前面的負號應該去掉?
2)對L({Wj},{u[i,j]})求偏導後,為什麼可以假設u[i,j]+u[j,i]=0從而將wj消去?
謝謝指正。
你可以試一下 的例子,未知數有4個:
的例子,未知數有4個: 。
。

 和
和 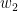 不為零向量),故
不為零向量),故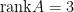 ,也就是說有無限多組解,故可設
,也就是說有無限多組解,故可設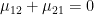 。同理,對於
。同理,對於 個未知數
個未知數  ,
,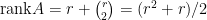 ,即有
,即有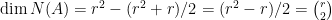 。所以我們可以放心地設
。所以我們可以放心地設 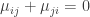 ,
,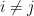 。
。
線性方程組為
係數矩陣A只有三個線性獨立的行向量(因為
突然想起在高中生時,我的數學老師常告誡我要將算式寫清楚。
老師,我還是有一些不明白。我自己推導一次後覺得u[i,j]+u[j,i]=0是必然發生的事,為什麼老師您要“設”呢?
啊,真的嗎?你有空時方便將過程貼上網或寄給我看看嗎?
左乘 ,
,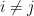 ,可得
,可得
上式不能推斷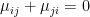 ,雖然
,雖然  ,但
,但 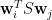 未必等於零。
未必等於零。
我說“推導”有些誇張了,其實我就寫了幾個步驟然後直覺地覺得,u[i,j]和u[j,i](i not equal to j)所對應的在A中的行向量必然一樣,所以所有形如
c * [0 0 … 1 … -1 0 …]’ 必然在A的零空間中,其中c為某一非零實數,1位於u[i,j]的位置,-1位於u[j,i]的位置。所有這些互為正交向量構成了A的零空間的基底,因此所有齊次解滿足u[i,j]+u[j,i]=0 if i is not equal to j。要令方程組成立,[Sw[1],…Sw[r]]’必須在X=span{W[1],…,w[r]}中,也就是說X是S的不變子空間。後來發現在推導的時候想當然地認為X就是S的特徵空間(eigenspace)所以必然有Sw[k]=lamda*w[k]從而得到方程組的特解中也必須有u[i,j]+u[j,i]=0 if i is not equal to j這個結論。我曾嘗試過證明X是滿足所有條件的唯一不變子空間但失敗了。
老師,不知道為什麼,我對這個假設沒有“安全感”,萬一該假設不成立那麼之後的證明就只有或然性而不是必然性了。
我明白了。沒有安全感是好事。朱熹說:「讀書,始讀未知有疑。其次則漸漸有疑,中則節節是疑。過了這一番后,疑漸漸解,以至融會貫通,都無所疑,方始是學。」
謝謝老師。
我們可以從另一個角度切入:根據註解二,待解的方程式為 ,
,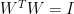 。因為
。因為  ,故可正交對角化為
,故可正交對角化為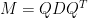 ,其中
,其中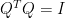 ,
,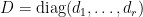 。代入可得
。代入可得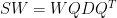 ,右乘
,右乘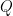 ,
,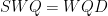 。令
。令 ,
, 。問題變成
。問題變成 ,也就是
,也就是 ,
, 。
。
W^T=W經過老師一點明果然豁然開朗。另外,老師的意思是因為M^T=M所以M可正交對角話吧。
非常感謝老師。
周老師,請問一下主成份分析和主成份回歸的關係為何?主成份回歸是否只是主成份分析的一個應用而已?
PCR (principal components regression) 就是 PCA+multiple regression。俗話說:蟑螂怕拖鞋,烏龜怕鐵鎚。在資料分析,線性模型怕共線性(collinearity),非線性模型怕過度擬合(over-fitting)。如果數據輸入矩陣X的維數很大(變數很多)且變數之間相關,則multiple regression的估計係數的變異很大(表示模型不可信賴)。為了解決這個問題,先對X進行主成分分析,取得低維數的主成分係數矩陣Z(各變數無關),透過適當的變數選擇方法(譬如計算輸出y和z_i的相關係數)挑選出一部分的z變數當作新的數據輸入,然後建模,再將估計出的z_i係數轉換回變數x_j的係數,此法稱為PCR estimator。詳見
http://en.wikipedia.org/wiki/Principal_component_regression
周老師 您好:
https://stats.stackexchange.com/questions/66926/what-are-the-four-axes-on-pca-biplot
目前資料分析使用主成分分析方法通常會畫一張叫做 biplot的圖來看看各筆資料在第一集第二主成分所組成的平面上到底比較受到哪一個原始參數的影響,在上述網頁中有提到這張圖到底是怎麼畫的,但是為什麼在biplot中的紅色箭頭向量並非只是主成分中各個變數佔的比例,而是還得乘上(主成分的解釋變異*資料筆數^(1/2))?
請參考
裡面的factor loading matrix
周老師,注釋3最後一個式子的第一項應該有個n-1的系數
非常謝謝,已訂正。