
本文的閱讀等級:中級
最佳化理論 (優化理論,optimization theory) 提供許多應用於社會、自然與工程科學的數值算法。給定一個目標函數或稱成本函數 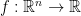

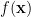
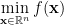
在一些應用場合,如果我們希望找到最大值,只要改變目標函數的正負號即可。對一般的目標函數 
令 




若 

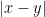
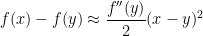
如果 


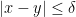
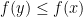
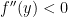
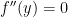
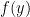


前述單變數分析可延伸至多變數問題,假設函數 

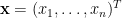

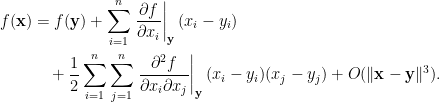
定義函數 



另定義 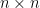

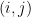
![[H(\mathbf{y})]_{ij}\overset{\underset{\mathrm{def}}{}}{=}\displaystyle\left.\frac{\partial^2f}{\partial x_i\partial x_j}\right|_{\mathbf{y}}](https://s0.wp.com/latex.php?latex=%5BH%28%5Cmathbf%7By%7D%29%5D_%7Bij%7D%5Coverset%7B%5Cunderset%7B%5Cmathrm%7Bdef%7D%7D%7B%7D%7D%7B%3D%7D%5Cdisplaystyle%5Cleft.%5Cfrac%7B%5Cpartial%5E2f%7D%7B%5Cpartial+x_i%5Cpartial+x_j%7D%5Cright%7C_%7B%5Cmathbf%7By%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
多變量泰勒定理可用矩陣形式表示為
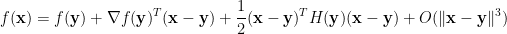
若 


使用導數法則,

可知 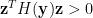
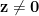

有兩個局部最大值在 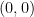
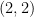

圖一 具有兩個局部最大值的函數
如果 

![H=\left[\!\!\begin{array}{cr} 2&0\\ 0&-2 \end{array}\!\!\right]](https://s0.wp.com/latex.php?latex=H%3D%5Cleft%5B%5C%21%5C%21%5Cbegin%7Barray%7D%7Bcr%7D++++2%260%5C%5C++++0%26-2++++%5Cend%7Barray%7D%5C%21%5C%21%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
因為 



圖二 具有一個鞍點的函數
給定一個可導實函數 


其中 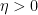


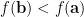
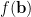

將梯度下降法給出的關係式 

不論 
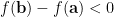
我將梯度下降法整理於下:給定一個初始點 
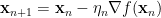
就有

適當選擇夠小的步伐 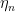

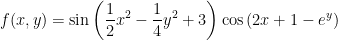
如果我們希望找尋局部最大值,可將梯度下降改為梯度上升 (gradient ascent),也就是選擇 

圖三 梯度上升過程
註解
[1] 取自維基百科http://en.wikipedia.org/wiki/Gradient_descent

老師,請問一下上面那個泰勒定理的多變量形式的二次項是否少了係數 1/2 呢?
謝謝指正。錯誤還不少,一併訂正了。
老師,文章的開頭,若y是f(x)的局部最小值,那麼對所有滿足|x-y|=f(y),不等號的方向反了吧?
感謝指正。難怪出版社需要editor,書寫者總是看不到自己的錯誤。
說來慚愧,我也是第二次讀老師的文章的時候才發現。