
本文的閱讀等級:中級
在線性代數的發展過程中,設計效率高且穩定性佳的矩陣特徵值算法是一個非常重要的研究問題。給定一個 


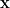



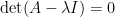



當 


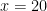




假如方陣 
Power 迭代法
- 給定一初始向量
- 對於
,直至
收斂止,計算
-
-


Power 迭代法的計算原理建立在差分方程上。當 




若 


![\displaystyle\mathbf{u}_k=\lambda_1^k\left[c_1\mathbf{x}_1+c_2\left(\frac{\lambda_2}{\lambda_1}\right)^k\mathbf{x}_2+\cdots+ c_n\left(\frac{\lambda_n}{\lambda_1}\right)^k \mathbf{x}_n\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cmathbf%7Bu%7D_k%3D%5Clambda_1%5Ek%5Cleft%5Bc_1%5Cmathbf%7Bx%7D_1%2Bc_2%5Cleft%28%5Cfrac%7B%5Clambda_2%7D%7B%5Clambda_1%7D%5Cright%29%5Ek%5Cmathbf%7Bx%7D_2%2B%5Ccdots%2B+c_n%5Cleft%28%5Cfrac%7B%5Clambda_n%7D%7B%5Clambda_1%7D%5Cright%29%5Ek+%5Cmathbf%7Bx%7D_n%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
對於 






數列 
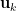

Power 法的優點是每個計算步驟僅需使用一次矩陣—向量乘法 



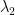
Power 迭代法的改良版稱為逆迭代法 (inverse iteration method),或移動逆迭代法 (shift inverse method),它與 Power 法的主要不同處在於以 
Power 移動逆迭代法
- 給定一初始向量
- 對於
-
-
-


純量 










我們可以由 Gershgorin 圓估計出的特徵值範圍設定鄰近

還有,計算 




Power 法和逆迭代法的主要應用在於計算大型稀疏矩陣 (包含許多零元) 的特徵值和特徵向量。如果我們想要得到完整的特徵值和特徵向量,或矩陣僅含少數的零元,這時便不宜採用 Power 迭代法。在一般情況下,QR 演算法是目前最常被採用的特徵值算法,這將留待日後再詳細介紹。
引用來源:
[1] http://en.wikipedia.org/wiki/Wilkinson%27s_polynomial

What if the matrix A has several same eigenvalues (for example, A has a Jordan block of (\lambda, 1), (0, \lambda))? What will the convergence rate be?
Let and
and  , where
, where 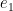 and
and 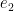 are standard unit vectors. If
are standard unit vectors. If  , the process converges immediately. Consider the case of
, the process converges immediately. Consider the case of  . Then,
. Then,

 ,
,  . The sequence converges sublinearly.
. The sequence converges sublinearly.
As
Note that the power method fails to converge if there are two different dominant eigenvalues with equal absolute value, for example, .
.