
本文的閱讀等級:中級
高斯消去法是當今最常被使用的線性方程解法 (見“高斯消去法”),它是一種直接法,即一次性地解決問題。對於一個 

考慮線性方程 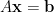

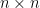
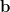






我們稱 
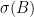





證明引用下列收斂矩陣性質:若 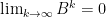
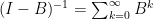
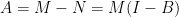

使用收斂矩陣性質,

既然定常迭代法的收斂性由 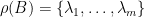


其中 



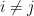


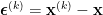

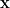

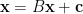
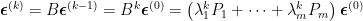
當 
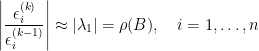
譜半徑 



故每次迭代的精確度改善量是 
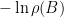
Jacobi 法
考慮線性方程 

若 
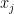


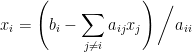
上式提示一個迭代公式,稱為 Jacobi 法:

Jacobi 法獨立看待每一個方程式,我們得以同時更新估計值,因此也稱為同時取代法 (method of simultaneous displacements)。如以矩陣表示,分解 


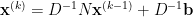
明顯地,
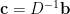
若 


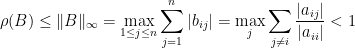
上面使用了 


Gauss-Seidel 法
在 Jacobi 法中,如果我們按照順序計算 

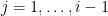

Gauss-Seidel 法按照既定的順序調整,因此也稱為逐次取代法 (method of successive displacements)。若以矩陣表示,分解 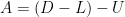


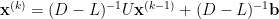
即 

類似 Jacobi 法,若 

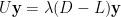



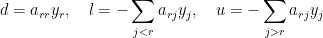
對角佔優矩陣 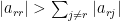

故 


證明
SOR 法
考慮 Gauss-Seidel 法,將迭代公式改寫為 


如果我們調整或「鬆弛」修正項,以 


稱為 SOR (successive overrelaxation) 法。以矩陣表達,分解 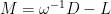

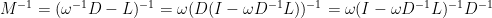
迭代矩陣為

SOR 法的矩陣表達式如下:

SOR 法引進鬆弛參數 


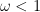
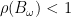
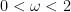

另一方面,


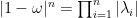
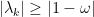

一般而言,除了少數特例,找尋使 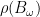
註解:
[1] 對角佔優矩陣雖保證 Jacobi 法和 Gauss-Seidel 法具備收斂性,但對角佔優是一個嚴苛的條件,並不常出現於現實應用。
[2] 證明見 Richard S. Varga 所著 Matrix Iterative Analysis,第二版,Springer,2000,頁83-84。

周老師您好 想請教 解線性方程Ax=b
自己在做數值 要收斂 一般都是 疊代次數>自訂次數 或 誤差<自訂誤差 時結束
想請教的是自訂誤差部分 要算向量的norm
我到的自訂誤差 為 ||b-A Xk||/||b-AX0|| 其中 X0為起始值 Xk為第K次疊代結果
要怎這解釋這個誤差
norm的計算是F (||.||F)
令 且
且  。所以相對殘量為
。所以相對殘量為

很多算法都採用上面的定義,不過,這個定義不適用於 接近零的情況。
接近零的情況。