
本文的閱讀等級:中級
機率 (概率) 學的研究始於隨機實驗。考慮投擲一顆六面骰子,樣本空間是所有可能出現點數形成的集合。為了分析機率模型,我們定義隨機變數 







- 機率質量函數 (probability mass function)
,即
的機率。在不造成混淆的情況下,我們經常稱機率質量函數為機率分布。
- 累積分布函數 (cumulative distribution function)
,即
。
本文將介紹第三種機率分布的描述方式,稱為動差生成函數或動差母函數 (moment generating function)。
對於一個離散型隨機變數 



其中 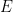


雖然 


上式指出 




上例中,

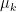

美國賓州大學教授維爾夫 (Herbert Wilf) 說[1]:「生成函數是一列用來展示一串數字的掛衣架。」動差生成函數是動差的一種簿記機制,它將動差 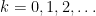

其中指數函數 
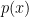
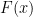
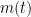





立得 
從外表很難想像一個隨機變數的動差生成函數是機率分布的另一種表達。下面我們證明若離散型隨機變數的值域為一有限集,則機率分布完全由動差決定。在此之前,我們必須先確定動差生成函數具有收斂性。
收斂性定理:令

收斂至一光滑函數 (smooth function),也就是無窮可導的函數。
證明於下。考慮動差的定義式

令 

最後一個等式使用了歸一性 


因此證明動差生成級數對於任一
唯一性定理:令
我們知道

令 




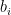
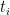

或以矩陣形式表示為 
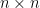
![\mathbf{A}=[a_{ij}]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BA%7D%3D%5Ba_%7Bij%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)


這種特殊形態矩陣稱為 Vandermonde 矩陣。因為所有的 

動差生成函數不具備內在含義,它的主要用途在於簡化計算。下面舉例說明如何從機率分布求得動差生成函數,並由一次和二次動差推導期望值和變異數。
例一:二項 (binomial) 分布
假設隨機變數 


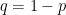

從

所以 

例二:卜瓦松 (Poisson) 分布
假設隨機變數 


從

所以 

關於其他類型的機率分布的動差生成函數請參考維基百科[2]。下面說明兩個實用的動差生成函數性質。
性質一:給定一隨機變數 

將

性質二:若 

若 

性質二的用途在於計算多個獨立隨機變數之和的機率分布,見下例。
例三:二項分布之和
假設 


故

例四:卜瓦松分布之和
假設 


故

最後我們總結離散型隨機變數的動差生成函數的兩個主要功用:
- 提供一個計算動差的快速方法;
- 提供一個推導多個獨立隨機變數之和的機率分布的簡易方法。
此外,離散型隨機變數的生成函數是解析分支過程 (branching process) 的一個重要工具,這個主題將獨立出來另文討論。下文將介紹連續型隨機變數的動差生成函數及其應用。
參考來源:
[1] 維基百科:Generating Function 原文是 “A generating function is a clothesline on which we hang up a sequence of numbers for display.”
[2] 維基百科:Moment Generating Function

写得好!之前学线性代数就来过这里。如有可能希望周老师增加些统计学的内容
線性代數寫的差不多了,現在是該考慮改弦易轍。
寫得真好欸
很詳細,也提供應用和證明,真是好
老師你好:
請問動差生成函數的收斂性在隨機變數X的值域是無窮集時也成立嗎?
因為文中的收斂性證明僅證明在有限集,而文末將動差生成函數應用在無窮集(卜瓦松分布)上
感謝
不好意思,我有一篇文章想引用您這份動差生成含數(上)的內容,作者名稱,您願意用周老師,還是ccjou呢? 亦或兩個都放上? 因為不知道您的本名,所以這樣冒昧的問您。
動差生成函數(上),抱歉打錯字