
本文的閱讀等級:中級
常態分布 (normal distribution),也稱高斯分布 (Gaussian distribution),其機率密度函數為

其中 



其中 

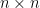

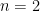

圖1 常態分布樣本
馬氏距離
常態分布的機率密度函數由下列二次型決定:

其中 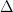
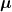
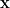


任何一個實方陣可分解為對稱矩陣與反對稱矩陣之和 (稱為卡氏分解),且反對稱矩陣的二次型必為零 (見“ 特殊矩陣 (13):反對稱矩陣”)。在不失一般性的原則下,假設 




- 特徵值
是實數,
- 單位特徵向量
組成一個單範正交集 (orthonormal set),即
若
,
若
。
令 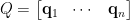
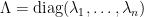
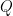
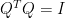

同樣地,逆共變異數矩陣亦可正交對角化為

將上式代入馬氏距離公式,

上面我們令 


可知 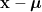
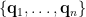




等高線
透過等高線 (contour line),我們可以視覺化常態分布的型態。為方便說明,考慮 

如果 







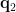

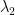



圖2 共變異數矩陣等高線:橢圓軌跡
對於 

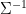

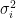



圖3 共變異數矩陣等高線
歸一性
我們證明多變量常態分布 





上式顯示

將仿射變換 
![J=\begin{bmatrix} \displaystyle\frac{\partial x_1}{\partial y_1}&\displaystyle\frac{\partial x_1}{\partial y_2}&\cdots&\displaystyle\frac{\partial x_1}{\partial y_n}\\[1em] \displaystyle\frac{\partial x_2}{\partial y_1}&\displaystyle\frac{\partial x_2}{\partial y_2}&\cdots&\displaystyle\frac{\partial x_2}{\partial y_n}\\ \vdots&\vdots&\ddots&\vdots\\ \displaystyle\frac{\partial x_n}{\partial y_1}&\displaystyle\frac{\partial x_n}{\partial y_2}&\cdots&\displaystyle\frac{\partial x_n}{\partial y_n} \end{bmatrix}=\begin{bmatrix} q_{11}&q_{12}&\cdots&q_{1n}\\ q_{21}&q_{22}&\cdots&q_{2n}\\ \vdots&\vdots&\ddots&\vdots\\ q_{n1}&q_{n2}&\cdots&q_{nn} \end{bmatrix}=Q](https://s0.wp.com/latex.php?latex=J%3D%5Cbegin%7Bbmatrix%7D++%5Cdisplaystyle%5Cfrac%7B%5Cpartial+x_1%7D%7B%5Cpartial+y_1%7D%26%5Cdisplaystyle%5Cfrac%7B%5Cpartial+x_1%7D%7B%5Cpartial+y_2%7D%26%5Ccdots%26%5Cdisplaystyle%5Cfrac%7B%5Cpartial+x_1%7D%7B%5Cpartial+y_n%7D%5C%5C%5B1em%5D++%5Cdisplaystyle%5Cfrac%7B%5Cpartial+x_2%7D%7B%5Cpartial+y_1%7D%26%5Cdisplaystyle%5Cfrac%7B%5Cpartial+x_2%7D%7B%5Cpartial+y_2%7D%26%5Ccdots%26%5Cdisplaystyle%5Cfrac%7B%5Cpartial+x_2%7D%7B%5Cpartial+y_n%7D%5C%5C++%5Cvdots%26%5Cvdots%26%5Cddots%26%5Cvdots%5C%5C++%5Cdisplaystyle%5Cfrac%7B%5Cpartial+x_n%7D%7B%5Cpartial+y_1%7D%26%5Cdisplaystyle%5Cfrac%7B%5Cpartial+x_n%7D%7B%5Cpartial+y_2%7D%26%5Ccdots%26%5Cdisplaystyle%5Cfrac%7B%5Cpartial+x_n%7D%7B%5Cpartial+y_n%7D++%5Cend%7Bbmatrix%7D%3D%5Cbegin%7Bbmatrix%7D++q_%7B11%7D%26q_%7B12%7D%26%5Ccdots%26q_%7B1n%7D%5C%5C++q_%7B21%7D%26q_%7B22%7D%26%5Ccdots%26q_%7B2n%7D%5C%5C++%5Cvdots%26%5Cvdots%26%5Cddots%26%5Cvdots%5C%5C++q_%7Bn1%7D%26q_%7Bn2%7D%26%5Ccdots%26q_%7Bnn%7D++%5Cend%7Bbmatrix%7D%3DQ&bg=ffffff&fg=000000&s=0&c=20201002)
利用 

因此 

證明
動差
首先,考慮單變量常態分布的動差 (moment)。令 

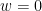
![\displaystyle \begin{aligned} \text{E}[x]&=\frac{1}{\sqrt{2\pi}\sigma}\int\exp\left\{-\frac{(x-\mu)^2}{2\sigma^2}\right\}xdx\\ &=\frac{1}{\sqrt{2\pi}\sigma}\int\exp\left\{-\frac{w^2}{2\sigma^2}\right\}(w+\mu)dw\\ &=\mu\frac{1}{\sqrt{2\pi}\sigma}\int\exp\left\{-\frac{w^2}{2\sigma^2}\right\}dw=\mu. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D++%5Ctext%7BE%7D%5Bx%5D%26%3D%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%5Csigma%7D%5Cint%5Cexp%5Cleft%5C%7B-%5Cfrac%7B%28x-%5Cmu%29%5E2%7D%7B2%5Csigma%5E2%7D%5Cright%5C%7Dxdx%5C%5C++%26%3D%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%5Csigma%7D%5Cint%5Cexp%5Cleft%5C%7B-%5Cfrac%7Bw%5E2%7D%7B2%5Csigma%5E2%7D%5Cright%5C%7D%28w%2B%5Cmu%29dw%5C%5C++%26%3D%5Cmu%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%5Csigma%7D%5Cint%5Cexp%5Cleft%5C%7B-%5Cfrac%7Bw%5E2%7D%7B2%5Csigma%5E2%7D%5Cright%5C%7Ddw%3D%5Cmu.++%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
因為

對 

上式等號兩邊同時乘以 
![\text{E}\left[(x-\mu)^2\right]=\sigma^2](https://s0.wp.com/latex.php?latex=%5Ctext%7BE%7D%5Cleft%5B%28x-%5Cmu%29%5E2%5Cright%5D%3D%5Csigma%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
接下來,我們討論多變量常態分布的動差並解釋參數 
![\displaystyle \begin{aligned} \text{E}[\mathbf{x}]&=\frac{1}{(2\pi)^{n/2}\vert\Sigma\vert^{1/2}}\int\exp\left\{-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^T\Sigma^{-1}(\mathbf{x}-\boldsymbol{\mu})\right\}\mathbf{x}d\mathbf{x}\\ &=\frac{1}{(2\pi)^{n/2}\vert\Sigma\vert^{1/2}}\int\exp\left\{-\frac{1}{2}\mathbf{w}^T\Sigma^{-1}\mathbf{w}\right\}(\mathbf{w}+\boldsymbol{\mu})d\mathbf{w}\\ &=\frac{1}{(2\pi)^{n/2}\vert\Sigma\vert^{1/2}}\left(\int\exp\left\{-\frac{1}{2}\mathbf{w}^T\Sigma^{-1}\mathbf{w}\right\}\mathbf{w}d\mathbf{w}+\boldsymbol{\mu}\int\exp\left\{-\frac{1}{2}\mathbf{w}^T\Sigma^{-1}\mathbf{w}\right\}d\mathbf{w}\right). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D++%5Ctext%7BE%7D%5B%5Cmathbf%7Bx%7D%5D%26%3D%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7Bn%2F2%7D%5Cvert%5CSigma%5Cvert%5E%7B1%2F2%7D%7D%5Cint%5Cexp%5Cleft%5C%7B-%5Cfrac%7B1%7D%7B2%7D%28%5Cmathbf%7Bx%7D-%5Cboldsymbol%7B%5Cmu%7D%29%5ET%5CSigma%5E%7B-1%7D%28%5Cmathbf%7Bx%7D-%5Cboldsymbol%7B%5Cmu%7D%29%5Cright%5C%7D%5Cmathbf%7Bx%7Dd%5Cmathbf%7Bx%7D%5C%5C++%26%3D%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7Bn%2F2%7D%5Cvert%5CSigma%5Cvert%5E%7B1%2F2%7D%7D%5Cint%5Cexp%5Cleft%5C%7B-%5Cfrac%7B1%7D%7B2%7D%5Cmathbf%7Bw%7D%5ET%5CSigma%5E%7B-1%7D%5Cmathbf%7Bw%7D%5Cright%5C%7D%28%5Cmathbf%7Bw%7D%2B%5Cboldsymbol%7B%5Cmu%7D%29d%5Cmathbf%7Bw%7D%5C%5C++%26%3D%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7Bn%2F2%7D%5Cvert%5CSigma%5Cvert%5E%7B1%2F2%7D%7D%5Cleft%28%5Cint%5Cexp%5Cleft%5C%7B-%5Cfrac%7B1%7D%7B2%7D%5Cmathbf%7Bw%7D%5ET%5CSigma%5E%7B-1%7D%5Cmathbf%7Bw%7D%5Cright%5C%7D%5Cmathbf%7Bw%7Dd%5Cmathbf%7Bw%7D%2B%5Cboldsymbol%7B%5Cmu%7D%5Cint%5Cexp%5Cleft%5C%7B-%5Cfrac%7B1%7D%7B2%7D%5Cmathbf%7Bw%7D%5ET%5CSigma%5E%7B-1%7D%5Cmathbf%7Bw%7D%5Cright%5C%7Dd%5Cmathbf%7Bw%7D%5Cright%29.++%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
指數函數 

![\displaystyle \text{E}[\mathbf{x}]=\boldsymbol{\mu}\int\mathcal{N}(\mathbf{w}\vert\mathbf{0},\Sigma)d\mathbf{w}=\boldsymbol{\mu}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctext%7BE%7D%5B%5Cmathbf%7Bx%7D%5D%3D%5Cboldsymbol%7B%5Cmu%7D%5Cint%5Cmathcal%7BN%7D%28%5Cmathbf%7Bw%7D%5Cvert%5Cmathbf%7B0%7D%2C%5CSigma%29d%5Cmathbf%7Bw%7D%3D%5Cboldsymbol%7B%5Cmu%7D&bg=ffffff&fg=000000&s=0&c=20201002)
因此我們稱 ![\text{E}[x^2]](https://s0.wp.com/latex.php?latex=%5Ctext%7BE%7D%5Bx%5E2%5D&bg=ffffff&fg=000000&s=0&c=20201002)
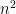
![\text{E}[x_ix_j]](https://s0.wp.com/latex.php?latex=%5Ctext%7BE%7D%5Bx_ix_j%5D&bg=ffffff&fg=000000&s=0&c=20201002)

![\text{E}[\mathbf{x}\mathbf{x}^T]](https://s0.wp.com/latex.php?latex=%5Ctext%7BE%7D%5B%5Cmathbf%7Bx%7D%5Cmathbf%7Bx%7D%5ET%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \text{E}\left[\mathbf{x}\mathbf{x}^T\right]&=\frac{1}{(2\pi)^{n/2}\vert\Sigma\vert^{1/2}}\int\exp\left\{-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^T\Sigma^{-1}(\mathbf{x}-\boldsymbol{\mu})\right\}\mathbf{x}\mathbf{x}^Td\mathbf{x}\\ &=\frac{1}{(2\pi)^{n/2}\vert\Sigma\vert^{1/2}}\int\exp\left\{-\frac{1}{2}\mathbf{w}^T\Sigma^{-1}\mathbf{w}\right\}(\mathbf{w}+\boldsymbol{\mu})(\mathbf{w}+\boldsymbol{\mu})^Td\mathbf{w}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D++%5Ctext%7BE%7D%5Cleft%5B%5Cmathbf%7Bx%7D%5Cmathbf%7Bx%7D%5ET%5Cright%5D%26%3D%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7Bn%2F2%7D%5Cvert%5CSigma%5Cvert%5E%7B1%2F2%7D%7D%5Cint%5Cexp%5Cleft%5C%7B-%5Cfrac%7B1%7D%7B2%7D%28%5Cmathbf%7Bx%7D-%5Cboldsymbol%7B%5Cmu%7D%29%5ET%5CSigma%5E%7B-1%7D%28%5Cmathbf%7Bx%7D-%5Cboldsymbol%7B%5Cmu%7D%29%5Cright%5C%7D%5Cmathbf%7Bx%7D%5Cmathbf%7Bx%7D%5ETd%5Cmathbf%7Bx%7D%5C%5C++%26%3D%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7Bn%2F2%7D%5Cvert%5CSigma%5Cvert%5E%7B1%2F2%7D%7D%5Cint%5Cexp%5Cleft%5C%7B-%5Cfrac%7B1%7D%7B2%7D%5Cmathbf%7Bw%7D%5ET%5CSigma%5E%7B-1%7D%5Cmathbf%7Bw%7D%5Cright%5C%7D%28%5Cmathbf%7Bw%7D%2B%5Cboldsymbol%7B%5Cmu%7D%29%28%5Cmathbf%7Bw%7D%2B%5Cboldsymbol%7B%5Cmu%7D%29%5ETd%5Cmathbf%7Bw%7D.++%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
上式中,









上式中,當 ![\hbox{E}\left[v_i^2\right]=\lambda_i](https://s0.wp.com/latex.php?latex=%5Chbox%7BE%7D%5Cleft%5Bv_i%5E2%5Cright%5D%3D%5Clambda_i&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \hbox{E}\left[\mathbf{x}\mathbf{x}^T\right]=\boldsymbol{\mu}\boldsymbol{\mu}^T+\Sigma](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Chbox%7BE%7D%5Cleft%5B%5Cmathbf%7Bx%7D%5Cmathbf%7Bx%7D%5ET%5Cright%5D%3D%5Cboldsymbol%7B%5Cmu%7D%5Cboldsymbol%7B%5Cmu%7D%5ET%2B%5CSigma&bg=ffffff&fg=000000&s=0&c=20201002)
類似單變量變異數,我們定義隨機向量
![\displaystyle \hbox{cov}\left[\mathbf{x}\right]=\hbox{E}\left[(\mathbf{x}-\boldsymbol{\mu})(\mathbf{x}-\boldsymbol{\mu})^T\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Chbox%7Bcov%7D%5Cleft%5B%5Cmathbf%7Bx%7D%5Cright%5D%3D%5Chbox%7BE%7D%5Cleft%5B%28%5Cmathbf%7Bx%7D-%5Cboldsymbol%7B%5Cmu%7D%29%28%5Cmathbf%7Bx%7D-%5Cboldsymbol%7B%5Cmu%7D%29%5ET%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
對於常態分布,利用 ![\text{E}[\mathbf{x}]=\boldsymbol{\mu}](https://s0.wp.com/latex.php?latex=%5Ctext%7BE%7D%5B%5Cmathbf%7Bx%7D%5D%3D%5Cboldsymbol%7B%5Cmu%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\begin{aligned} \hbox{cov}[\mathbf{x}]&= \hbox{E}\left[\mathbf{x}\mathbf{x}^T-\mathbf{x}\boldsymbol{\mu}^T-\boldsymbol{\mu}\mathbf{x}^T+\boldsymbol{\mu}\boldsymbol{\mu}^T\right]\\ &=\hbox{E}\left[\mathbf{x}\mathbf{x}^T\right]-\text{E}[\mathbf{x}]\boldsymbol{\mu}^T-\boldsymbol{\mu}\text{E}\left[\mathbf{x}\right]^T+\boldsymbol{\mu}\boldsymbol{\mu}^T\\ &=\hbox{E}\left[\mathbf{x}\mathbf{x}^T\right]-\boldsymbol{\mu}\boldsymbol{\mu}^T=\Sigma,\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++%5Chbox%7Bcov%7D%5B%5Cmathbf%7Bx%7D%5D%26%3D++%5Chbox%7BE%7D%5Cleft%5B%5Cmathbf%7Bx%7D%5Cmathbf%7Bx%7D%5ET-%5Cmathbf%7Bx%7D%5Cboldsymbol%7B%5Cmu%7D%5ET-%5Cboldsymbol%7B%5Cmu%7D%5Cmathbf%7Bx%7D%5ET%2B%5Cboldsymbol%7B%5Cmu%7D%5Cboldsymbol%7B%5Cmu%7D%5ET%5Cright%5D%5C%5C++%26%3D%5Chbox%7BE%7D%5Cleft%5B%5Cmathbf%7Bx%7D%5Cmathbf%7Bx%7D%5ET%5Cright%5D-%5Ctext%7BE%7D%5B%5Cmathbf%7Bx%7D%5D%5Cboldsymbol%7B%5Cmu%7D%5ET-%5Cboldsymbol%7B%5Cmu%7D%5Ctext%7BE%7D%5Cleft%5B%5Cmathbf%7Bx%7D%5Cright%5D%5ET%2B%5Cboldsymbol%7B%5Cmu%7D%5Cboldsymbol%7B%5Cmu%7D%5ET%5C%5C++%26%3D%5Chbox%7BE%7D%5Cleft%5B%5Cmathbf%7Bx%7D%5Cmathbf%7Bx%7D%5ET%5Cright%5D-%5Cboldsymbol%7B%5Cmu%7D%5Cboldsymbol%7B%5Cmu%7D%5ET%3D%5CSigma%2C%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
即證明
Cholesky 分解與極分解
運用矩陣分解可以從另一個角度認識常態分布和共變異數矩陣。考慮 





令 



稱為標準常態分布,平均數向量是 



解釋如下:先伸縮標準常態分布的隨機向量 

圖4 從標準常態分布至一般常態分布
註解
[1] 中央極限定理 (central limit theorem):如果從平均數為 

[2] 考慮單變量的高斯積分

將積分平方,運用換元積分法,如下:

其中使用變數變換 



也就有


周老師,今天我收到通知我們學校這個星期四有一個Dissertation Proposal Defense,關於central matrix method in dimension reduction regression。我google了一下沒找到相關資料。是不是這個method有其他的名字?
central matrix based method 不是一個公認的名稱,我僅查找到一篇文章:
http://onlinelibrary.wiley.com/doi/10.1002/cjs.11181/abstract
可能是 Sliced inverse regression 的變形:
http://en.wikipedia.org/wiki/Sliced_inverse_regression
謝謝老師。
老師,請問一下若是兩變數獨立的話,共變異數矩陣是不是一個只有對角線上有值,上三角和下三角都是零的矩陣?
是的,相關討論見