
本文的閱讀等級:高級
在許多現實應用中,我們往往要面對高維度 (多變數) 數據,為便利分析,降維 (dimension reduction) 常是一個必要的前處理工作。主成分分析 (principal components analysis) 是目前普遍被採用的降維技術 (見“主成分分析”)。主成分分析是一種非教導式學習法 (unsupervised learning),根據樣本自身的統計性質降維,並不在乎 (甚至不知道) 這些數據的後續應用。在機器學習領域,分類 (classification) 與回歸 (regression) 是兩個最具代表性的問題描述典範。所謂分類是指識別出數據點所屬的類別。本文介紹英國統計學家費雪 (Ronald Fisher) 最早提出的一個專為包含兩個類別樣本所設計的教導式 (supervised) 降維法,稱作費雪的判別分析 (Fisher’s discriminant analysis),隨後並討論三個延伸問題:
- 甚麼是線性判別分析 (linear discriminant analysis)?它與費雪的判別分析有何關係?
- 線性判別分析與最小平方法有甚麼關聯性?
- 費雪的判別分析如何推廣至多類別 (類別數大於2) 判別分析?

Ronald Fisher (1890-1962) From http://upload.wikimedia.org/wikipedia/commons/4/46/R._A._Fischer.jpg
費雪的判別分析
假設我們有一筆維數等於 

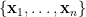

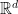
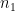
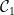
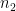


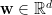



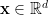

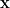

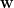


根據上式,令 

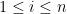

直覺上,為了獲致最好的分類效果,我們希望分屬兩類別的數據點的投影距離越遠越好。寫出兩個類別數據點的各自樣本中心 (樣本平均數向量):

投影量的樣本平均數就是樣本中心的投影,如下:

因此,兩類別的樣本中心投影的距離為
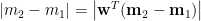
由於我們已經加入限制 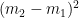

其中 
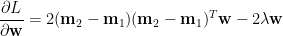
令上式等於零,因為 


二類別數據點投影至不同的直線
定義兩類別的投影樣本的組內散布 (within-class scatter) 為

將組內散布 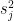

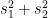
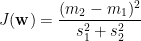
下面解說如何求出使上式最大的單位向量
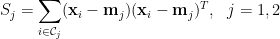
以及整體組內散布矩陣 



整體組內散布即為

類似地,定義組間散布矩陣

組間散布 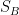
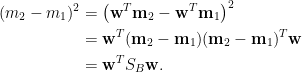
組內散布矩陣 (在不造成混淆的情況下,整體組內散布矩陣簡稱為組內散布矩陣) 
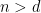
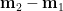

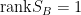
使用組間散布和組內散布的二次型表達,費雪準則可用矩陣式表示為

最大化費雪準則等價於下列約束優化問題 (見“Hermitian 矩陣特徵值的變化界定”):

使用 Lagrange 乘數法不難推導出最佳條件式。這裡我們介紹一個線性代數方法:費雪準則也稱為廣義 Rayleigh 商,最大化 

由於 


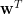




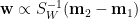
直白地說,最佳投影直線的指向即為連接兩類別樣本中心的向量於排除組內散布效應後的方向 (如上圖右所示)。
線性判別分析
費雪的判別分析其實是一個應用於兩類別樣本的降維方法,它本身並不具備判別功能。如欲將費雪的判別分析引進分類功能,我們還須決定分類法則 


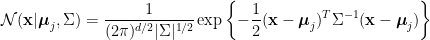
其中 

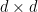
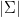
給定一數據點

其中
是類別
是條件密度函數,即給定類別
是數據點
;
是指在給定數據點
所謂貝氏最佳分類器就是將數據點 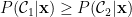
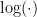

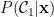

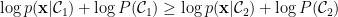
考慮第一類數據點

乘開化簡可得
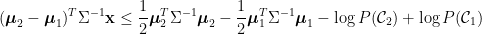
因此,線性判別分析的分類法則如下:若

給定一訓練樣本,先驗機率 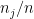

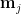

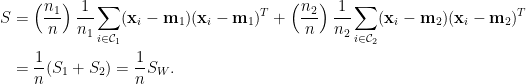
採用估計量的線性判別分析給出

這與費雪的判別分析的最佳直線有相同的指向,同時並確定了判別門檻

最小平方法
線性判別分析給出分隔兩類別的線性邊界 
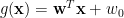


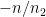

其中 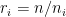

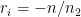


令上面兩式為零。由 
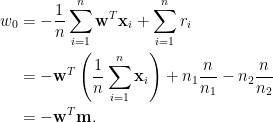
將解得的 

展開即有

不計純量,則得
因為 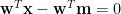
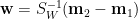


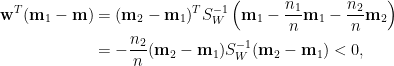
上面不等式係因 
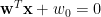
多類別判別分析
費雪的判別分析限定於包含兩類別的樣本,後續學者將它推廣至 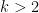
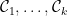


其中
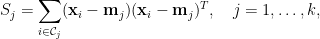
且

上式中 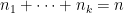
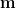



使用上面兩式化簡整體散布矩陣

這個結果提示了組間散布矩陣可定義為 (此定義於先前二類別定義的差異見註解[2])

即有,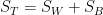
我們引進 
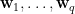


或合併為矩陣形式

其中 

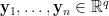
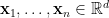




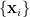



其中
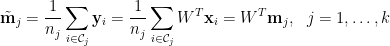

定義於

接下來將定義於兩類別的費雪準則推廣至

和

有趣的是,這兩個準則有相同的最佳條件:
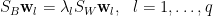
其中 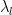





因為加入零特徵值不會加大 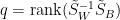


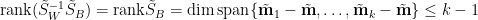
故 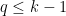
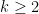
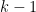
在確保樣本保有最佳分類效果的前提下,多類別判別分析將 
註解
[1] 先證明下列等式:

直接乘開組內散布矩陣

故 
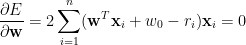
代入 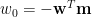
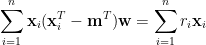
等號左邊化簡如下:

等號右邊為
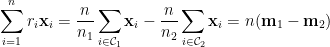
[2] 對於兩類別情況 (即

其中

因此,

上式與費雪的判別分析使用的二類別的組間散布矩陣的差異僅在於 
[3] Christopher M. Bishop, Pattern Recognition and Machine Learning, Springer, 2006, pp 192.
[4] Richard O. Duda, Peter E. Hart, and David G. Stork, Pattern Classification, 2nd ed., John Wiley & Sons, 2001, pp 123.
[5] 對於目標函數

使用跡數的導數恆等式 (見“跡數與行列式的導數”,tr-20),
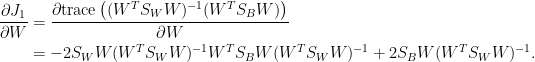
令 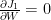

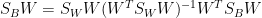
或表示為

我們需要這個性質: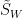
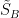

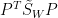
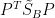

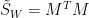

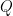






且

將上面二式改寫為 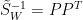
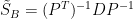
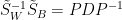
也就是說
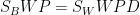
令 

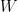

對於任何可逆矩陣 
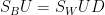
以行向量表示 

我們推得一個重要的結論:
[6] 對於目標函數

取對數可得

這麼做的原因是對數函數不會改變極值的位置。使用行列式的導數恆等式 (見“跡數與行列式的導數”,det-10),
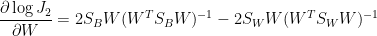
令 

此即註解[5]所導出的最佳條件式。以
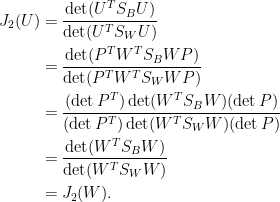
這說明 

本文過長,我校讀過二遍,如果讀者發現仍有錯誤請不吝指正,謝謝。
周老師,我有個疑問:
文中,“直白地說,最佳投影直線的指向即為連接二個類別樣本中心的向量於排除組內散布效應後的方向 (如上圖左所示)。”
這裡是否應該是“如上圖右所示”?
謝謝,你眼力真好!我後來也發現了這個錯誤,已訂正。還有沒有別的錯誤?特別是註解,記號實在非常繁雜。
老師,我剛才把註解部分看了一遍,覺得應該沒有任何問題。
謝謝老師的文章,令我對LDA背後的理論有更深刻的理解。
周老師您好
您提到在兩類別資料中求取w時
如果 n>d,Sw 通常是正定矩陣
此時的特例應該是n>d時資料矩陣還是可能是 singular matrix
而原本應是求解廣義特徵值問題也因為 Sw與Sb 的inverse不存在而無法轉換
因此想請問您有甚麼辦法能在不刪除線性相依變數的前提下進行LDA呢?
如果 是不可逆矩陣,你可以在主對角元加入一個很小的擾動量
是不可逆矩陣,你可以在主對角元加入一個很小的擾動量  ,成為
,成為  。不過,解出的
。不過,解出的  將隨
將隨  的大小改變。
的大小改變。
周老師,我有兩個的疑問:1多分類情況的目標函數的含義。以不相互正交基底的共變異數矩陣的行列式的意義?2多分類下,最大特征值對應的特征向量分割性能最好,最小特征值對應的特征向量分割性能最差,為什麼還要選它呢?
1) 矩陣的行列式等於所有特徵值之積;
2) 這些特徵向量都是兩兩正交,即便特徵值小的特徵向量仍具備分割能力。
謝謝周老師的介紹,實在非常詳盡,含括大部分推導細節,很棒的文章,受益良多。
發現一個很小的錯誤,但不影響其他式子的推導:在線性判別分析,一開始提到的多變量常態分布函數,$(2\pi)$的指數應是$\frac{d}{2}$喔。
Pingback: 費雪的判別分析與線性判別分析 | 不分享空間
你好, 我觉公式3 可以写成arg max trace(A)/trace(B), 这样求导更简单,而不必是arg max trace(inv(A)B)